Na vijf jaar is het zover – op 26 januari gaat het kroniekencorpus ‘live’ op https://kronieken.transkribus.eu. We publiceren dan 207 kroniekteksten, meer dan 23 miljoen woorden online, integraal doorzoekbaar en voor iedereen toegankelijk. 82 van deze teksten waren al te vinden op DBNL, maar waren niet eerder doorzoekbaar samen met de anderen. De andere 125 zijn, dankzij de noeste arbeid van het team, erfgoedinstellingen, nieuwe technologie en heel veel vrijwilligers en studenten nu voor het eerst in transcriptie beschikbaar.
Met deze unieke collectie kunnen we tijdreizen naar het leven in dorpen en steden in Nederland en Vlaanderen tussen 1500-1850. Kroniekschrijvers daar schreven wat ze meemaakten in oorlogen, opstanden, en epidemieën, maar ook over wat ze verder memorabel vonden. In Amsterdam proost men met ‘koffijwater’ op de geboorte van een Oranjeprins, in Brugge wordt Romeo en Julia gespeeld. In Lokeren brandt de kerk af, in Wirdum vraagt men zich af of een bliksemafleider zin heeft en in Oostzaan gaat een wonderschip te water.
In ons onderzoeksteam deden we al veel mooi onderzoek met deze collectie, maar er is nog veel meer mogelijk. Niet alleen wetenschappers en studenten kunnen de kronieken benutten, maar er liggen ook allerlei mogelijkheden voor lokale onderzoekers en historische verenigingen. Wie daar meer over wil horen is van harte welkom op het symposium waarop we de collectie feestelijk lanceren, in het Amsterdamse Trippenhuis. Programma en informatie over aanmelding vind je op https://www.knaw.nl/bijeenkomsten/kronieken-digitaal-een-nieuwe-toekomst-voor-oud-nieuws. De bijeenkomst kan ook worden gevolgd via een livestream, https://www.youtube.com/watch?v=x-KKwCCdndg
Hoe beleven kroniekschrijvers de tijd waarin ze leven? Komt hun vorm van lokale geschiedschrijving overeen met de wijze waarop wij ons nationale gebeurtenissen herinneren? En kunnen kroniekschrijvers ons op vergeten momenten in de geschiedenis wijzen? Alie Lassche, PhD-kandidaat in het project Chronicling Novelty legt uit hoe ze tijdens haar onderzoeksverblijf aan het Center for Humanities Computing in Aarhus deze vragen probeert te beantwoorden, en welke rol de door vrijwilligers aangebrachte labels in het corpus daarin spelen.
Iedereen die wel eens een kroniek heeft gelezen, weet dat het een bron is waarin een breed palet aan informatie bij elkaar komt. Het ene moment praat een kroniekschrijver je bij over de prijzen van het graan op de markt, het volgende moment wordt de verschijning van een komeet beschreven, dan weer volgt er een wat droge samenvatting van de vergadering van de schepenen. Anderen vertrouwen hun zorgen omtrent een besmettelijke koeienziekte aan het papier toe, en weer een ander zorgt ervoor dat alle nieuwtjes en roddels aangaande het reilen, zeilen, rouwen en trouwen in diens stad of dorp vastgelegd worden. En dan zijn er nog de nationale ontwikkelingen: een oorlog met Spanje in de zestiende en zeventiende eeuw, het beleg van diverse steden door de Fransen eind achttiende eeuw – er gebeurt veel in de Nederlandse Republiek in een periode van 350 jaar.
Veel van die gebeurtenissen kennen we natuurlijk uit de nationale geschiedschrijving. Bovendien worden veel van die gebeurtenissen tegenwoordig nog herdacht. Zo is er momenteel volop aandacht voor 1572, dat als het geboortejaar van Nederland wordt gezien, en als een keerpunt in de Tachtigjarige Oorlog. We herinneren ons 1572 als een jaar waarin de strijd tussen Spanje en de Nederlandse Republiek in alle hevigheid woedt, maar, zo laten Judith Pollmann en Ramon Fagel al weten in de ondertitel van hun recent verschenen boek: er woedde vooral een burgeroorlog in de Nederlanden. In bijna elke stad heerst er spanning en onenigheid over welke partij er gekozen moest worden. Kortom: onze herinnering aan gebeurtenissen in het verleden komt lang niet altijd overeen met de daadwerkelijke ervaringen van de mensen die destijds leefden.
Wat een fijn stapeltje! Vandaag bij mij thuis, morgen in de boekhandel: 1572. Burgeroorlog in de Nederlanden. Co-productie met @LeidenHum collega Raymond Fagel bij @prometheusbb, en onze bijdrage aan het herdenkingsjaar @geboortevan_nlpic.twitter.com/vVKzZA09Ee
Een kroniek is daarom een unieke bron: het geeft een lokaal inkijkje in een periode die lang achter ons ligt. Een grote verzameling kronieken, zoals bij elkaar gebracht in het project Chronicling Novelty, is daarom een kostbare schat. We kunnen er tal van vragen mee beantwoorden, waaronder: in hoeverre komt de manier waarop we ons historische gebeurtenissen anno nu herinneren overeen met de manier waarop ze worden beschreven door kroniekschrijvers? En is het misschien mogelijk dat het lokale en persoonlijke perspectief van een kroniekschrijver ons op gebeurtenissen wijst die ietwat zijn ondergesneeuwd of misschien zelfs nooit opgenomen in de geschiedschrijving?
In mijn onderzoek gebruik ik computationele methoden om deze (en andere) vragen te beantwoorden. Momenteel doe ik dat niet aan de Universiteit Leiden, maar aan het Center for Humanities Computing in Aarhus, een charmante havenstad in Midden-Jutland, Denemarken. Samen met Jan Kostkan en Kristoffer Nielbo werk ik aan het detecteren van events in het kroniekencorpus. Van alle labels die door veel vrijwilligers in de laatste twee jaren zijn toegevoegd aan het corpus, is in dit onderzoek het datumlabel in het bijzonder relevant. Wanneer een kroniekschrijver een datum vermeldt – ‘de eerste der Hooijmaand’, ’16 Xbris’ of gewoon ’17 Februari’, is daar een label aan toegevoegd, waarin de genormaliseerde datum is opgenomen. Dat ziet er zo uit in de XMLs, de files waarmee wij werken:
Met behulp van computercode splitsen we kronieken op in kleinere fragmenten: elke keer als we een datumlabel tegenkomen, wordt er geknipt. Zo ontstaan er tal van kroniekfragmenten, die allemaal beginnen met een datum. Een event is in deze context een fragment dat gekoppeld kan worden aan een datum. Vervolgens groeperen we fragmenten van dezelfde datum bij elkaar. Voor elke datum krijgen we zo een verzameling events, geschreven op dezelfde dag, door verschillende kroniekschrijvers. In onderstaande grafiek zijn de events voor de leesbaarheid per decennium gegroepeerd en geteld. De lichte kleur zijn het aantal unieke events in dat decennium (één fragment voor een datum), de donkere kleur zijn het aantal niet-unieke events (meerdere fragmenten van dezelfde datum):
We kunnen nu bijvoorbeeld zien dat het corpus veel events bevat uit de beginjaren van de Tachtigjarige Oorlog, en dat daarnaast de jaren 1660 goed vertegenwoordigd zijn. Let op: voor het maken van deze grafiek is een gedeelte van het totale corpus gebruikt (ongeveer 80 kronieken), en zijn alleen de volledige datumlabels gebruikt (en dus niet een label waarin enkel het jaar en de maand is gespecificeerd, zoals in 1572-04-xx of 1743-xx-xx).
Natuurlijk zijn er tal van beperkingen die de vroegmoderne kronieken en deze methode met zich meebrengen. Zo zijn er bijvoorbeeld kroniekschrijvers die hun kroniek beginnen met de schepping van Adam in wat zij als jaar 0 beschouwen. Als je op die manier doorrekent, gebeurt er iets heel anders in het jaar 1572 dan verwacht. Daarnaast verwijst een kroniekschrijver soms terug naar een moment eerder in de geschiedenis, wat er voor kan zorgen dat het datumlabel 1572-04-01 wordt opgevolgd door 1566-03-05. We zijn voortdurend bezig met het definiëren van oplossingen voor zulke uitdagingen.
In een volgende stap kijken we naar de inhoud van de events, dus naar dat wat er beschreven wordt. Gaan alle fragmenten uit het jaar 1577 over de oorlog met Spanje, of zijn er auteurs die in deze periode over heel andere gebeurtenissen schrijven? Wordt de piek aan events in 1668 veroorzaakt door één belangrijke gebeurtenis, of is het in feite een opstapeling van totaal verschillende events, omdat de één een belegering door de Fransen beschrijft, een volgende de mislukte oogst, en een derde over de schepenvergaderingen rapporteert?
Om daar achter te komen, moeten we de fragmenten op zo’n manier representeren, dat we ze eenvoudig met elkaar kunnen vergelijken. Daarvoor gebruiken we een embedding model. In zo’n model wordt een woord of tekst uitgedrukt als een vector (dat is: een reeks getallen) in een multidimensionale ruimte. Woorden of teksten die semantisch gerelateerd zijn, worden dichtbij elkaar geplaatst. De Python-package Top2Vec is een manier om dit te doen, en het is een van de modellen waarmee we momenteel experimenteren. Top2Vec plot zowel de documentvectoren als de woordvectoren in dezelfde ruimte, en detecteert vervolgens gebieden waar veel documenten gegroepeerd zijn. Zo’n ‘dichtbevolkt’ gebied bestaat uit documenten die vergelijkbaar met elkaar zijn, evenals de woorden die het meest onderscheidend zijn voor die documenten. Die meest onderscheidende woorden worden beschouwd als een topic.
Het meest prominente topic in een van de eerste getrainde Top2Vec-modellen bestaat uit de volgende woorden:
Dit topic gaat duidelijk over het weer. Events die over het weer gaan, zullen zich in de multidimensionale ruimte dicht bij dit topic bevinden. We drukken dit uit in cosine similarity, een getal tussen de -1 en de +1. Een cosine similarity tussen een document en een topic nabij +1 betekent dat het document heel erg vergelijkbaar is met het topic, terwijl een waarde nabij -1 het omgekeerde betekent. Wanneer we vervolgens de gemiddelde cosine similarity (na scaling) van alle documenten ten opzichte van dit topic plotten, ziet dat er als volgt uit:
De lijn blijft de eerste tweehonderd jaar rond een y-waarde van 0 schommelen, wat betekent dat het weer een constant onderwerp is in de kronieken uit die tijd. Daarna zien we een opvallende stijging, die zou betekenen dat er vanaf 1650 aanzienlijk meer over het weer wordt geschreven. Het is zaak om geen overhaaste conclusies te trekken uit zo’n grafiek, maar ook te kijken naar de ontwikkeling van andere (vergelijkbare) topics, en naar de karakteristieken van het gebruikte corpus: zijn de kronieken van de laatste 150 jaar niet toevallig voornamelijk geschreven door boeren, voor wie het weer een belangrijke rol speelt in hun dagelijks leven en inkomen? Ook dat is iets waar we in de komende tijd verdere aandacht aan zullen besteden.
Wat ik hierboven heb beschreven, is natuurlijk nog lang geen afgerond onderzoek. Deze eerste onderzoeksresultaten zijn slechts heel kleine stukjes van een puzzel die nog grotendeels gelegd moet worden. De gestelde onderzoeksvragen zijn nog niet beantwoord – in plaats daarvan zijn er misschien juist nog meer vragen bij gekomen. Het wil echter wel laten zien dat de systematische manier waarop we hier in Aarhus deze bronnen van informatie bestuderen heel spannende resultaten kan opleveren. Daarnaast laat het zien hoe belangrijk het werk van vrijwilligers is, die nog steeds dagelijks aan het transcriberen, annoteren en corrigeren zijn. Samen krijgen we zo steeds meer inzicht in de gebeurtenissen en onderwerpen die van belang waren voor de vroegmoderne middenklasse in de Nederlandse Republiek.
Op woensdag 22 december 2021 hebben we het eerste algemene model gepubliceerd voor het automatisch herkennen van zeventiende-eeuwse Nederlandse handschriften!
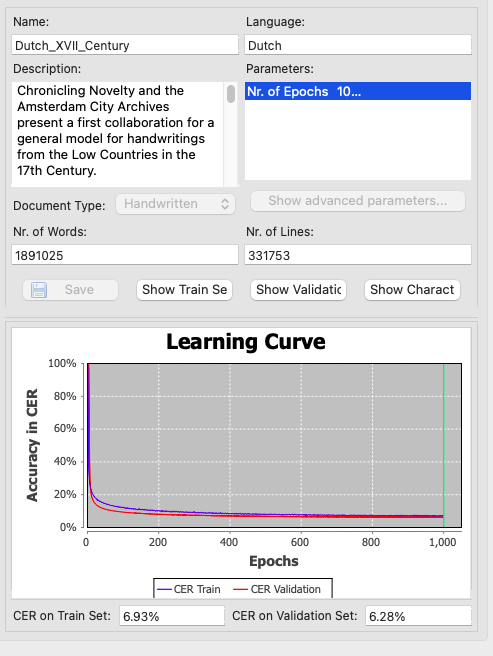
De afgelopen jaren hebben vrijwilligers op Vele Handen heel veel scans getranscribeerd in ons project Nieuws! Lokale kronieken, 1500-1850 en ook in het project van het Amsterdamse Stadsarchief Crowd Leert Computer Lezen. Een groot deel van deze scans is nu gebruikt om de computer te trainen in het lezen van die lastige 17e-eeuwse handschriften. Het resultaat is een algemeen HTR (Handwritten Tekst Recognition) model Dutch_XVII_Century dat vandaag voor alle gebruikers van Transkribus gratis beschikbaar is gemaakt.
Eerder publiceerde het Nationaal Archief al zo’n algemeen model (IJsberg) voor de hele periode 1600-1800 en samen met het Stadsarchief Amsterdam kwam er zo’n algemeen model voor de 18e eeuw, (Dutch Mountains). Beide modellen deden het nog niet goed op gotische handschriften. Daarom wilden we een model trainen op basis van uitsluitend gotische handschriften. Zeventiende-eeuwse handschriften zijn voor een leek niet te lezen en ook doorgewinterde historici worstelen er nog wel mee.
Dutch_XVII_Century
In het nieuwe Transkribusmodel ‘Dutch_XVII_Century’ is een evenwichtige balans gezocht tussen handschriften van enerzijds Crowd Leert Computer Lezen en anderzijds Chronicling Novelty. Per handschrift zijn niet meer dan 300 scans aan dit algemene model toegevoegd. Het Stadsarchief Amsterdam leverde op deze manier trainingsmateriaal aan van veertien zeventiende-eeuwse notarissen: Bruijningh, Mathijsz, Westfrisius, Schaef, De Winter, Van der Groe, Anthony van de Ven, Van Sevenhoven, Des Pommare, Borsselaer, Pondt, De Vos, Joost van de Ven en Venkel. Chronicling Novelty leverde twintig verschillende kronieken, te weten uit: Antwerpen (1643), Den Bosch (1604), Brugge (1675, 1684), Brussel (1681), Gent (1666, 1668, 1668), Hauwert (1636), Ieper (1695), Leeuwarden (1671, 1697), Mechelen (1657, 1665), De Rijp (1652), Rotterdam (1648, 1658, 1663, 1690) en Zwolle (1681). In totaal bestaat het trainingsmateriaal voor het model ‘Dutch_XVII_Century’ uit scans 2965 van notarisakten en 1877 scans van kronieken. Samen goed voor 4842 scans met daarop 1.891.025 getranscribeerde woorden. Daarmee is het in één klap het grootste model voor Nederlandstalig materiaal en behoort het tot de grootste modellen in Transkribus.
Probeer het heel eenvoudig zelf uit!
‘Dutch_XVII_Century’ werkt al heel aardig. De foutenmarge (ook wel Character Error Rate –kortweg CER- genoemd) bedraagt 6,28%. Het is getest op andersoortig materiaal zoals dagboeken en akten en de resultaten daarvan zijn veelbelovend. Nieuwsgierig geworden hoe goed dit model uw zeventiende-eeuwse bronnen transcribeert? Test dan hier of hier het nieuwe model (respectievelijk HTR+ en PyLaia)!
In de aanloop naar de publicatie van dit model zijn het Stadsarchief Amsterdam en Chronicling Novelty in gesprek geweest met diverse andere partijen die momenteel veel handgeschreven materiaal uit de zeventiende eeuw verwerken in Transkribus. Het idee is om in de toekomst met meer partijen samen te werken aan algemene modellen zodat we die CER verder omlaag krijgen en nog meer mensen hun lastig leesbare handschriften automatisch kunnen transcriberen in Transkribus.
Twee jaar geleden zijn we van start gegaan met een ambitieus project: Chronicling Novelty – het ontsluiten van zo’n driehonderd kronieken uit de periode 1500-1850. Als eerste stap bezochten we tientallen archieven en fotografeerden daar vele duizenden pagina’s aan kronieken. Vervolgens plaatsten we deze foto’s op VeleHanden, waar onze vrijwilligers elke dag bezig zijn om pagina na pagina te transcriberen, of door de computer gemaakte transcripties te controleren. In de afgelopen twee jaar is er al zoveel werk verzet, dat we graag willen laten zien wat het grote geheel is waaraan iedereen zijn of haar steentje bijdraagt.
De afgelopen maanden zijn we bezig geweest met het maken van een filmpje, dat een uniek kijkje in de keuken geeft van ons project. We laten zien hoe een kroniek, vanaf een plank in het archief, met behulp van een scantent en een grote poule vrijwilligers, uiteindelijk digitaal beschikbaar wordt. Het resultaat is meervoudig: wij als onderzoekers van het project Chronicling Novelty kunnen nu het medialandschap van kroniekschrijvers en de receptie van innovatie onderzoeken. Daarnaast kan iedereen vanuit zijn of haar eigen werk- of huiskamer een tijdreis maken en met een kroniekschrijver meewandelen door de straten en stegen van diens dorp of stad. Bovendien worden deze kronieken dankzij dit digitaliseringsproject ook beschikbaar voor andere onderzoekers.
Het filmpje laat zien dat we in hoge mate afhankelijk zijn van het werk dat door de vrijwilligers wordt gedaan. We zetten hen op deze manier daarom graag in het middelpunt. Bovendien maken we graag nieuwe vrijwilligers enthousiast om ook mee te helpen met ons project en zo oud nieuws een digitale toekomst te geven. Bekijk het filmpje hier:
Ben je nieuwsgierig geworden en wil je je steentje bijdragen? Bekijk ons project op VeleHanden en schrijf je in als vrijwilliger!
Terwijl iedereen zich steeds meer terugtrekt in zijn of haar thuiskantoor en de uren aan elkaar Zoomt, timmeren wij als team ‘Chronicling Novelty’ een flinke metaforische mijlpaal de bodem in. Sinds we in september 2018 begonnen met het verzamelen en scannen van allerlei kronieken uit diverse archieven in Nederland en België, is er een heleboel gebeurd. Zoveel, dat we nu kunnen zeggen: ons corpus is compleet! Graag vertellen we daar wat meer over. Daarnaast geven we een update over de volgende stappen die we gaan zetten, en hoe we uw en jouw hulp daarbij goed kunnen gebruiken.
Over het corpus
Ons corpus bevat 308 kronieken, en dat is inclusief de afzonderlijke delen die sommige auteurs hebben geproduceerd. De totale kroniekenlijst is hier te vinden, geordend per provincie. In totaal zijn 239 verschillende auteurs verantwoordelijk voor deze manuscripten, en daarvan zijn 52 auteurs anoniem. Dat betekent dat we van 256 kronieken weten door wie ze geschreven zijn. In sommige gevallen is dat enkel een naam, maar in veel gevallen weten we ook het geboorte- en sterfjaar van de auteur, en wat zijn of haar professie en religie was. Op onderstaande afbeelding is de geografische spreiding van het corpus in kaart gebracht.
Geografische spreiding van het corpus.
Niet al die 308 kronieken hoeven overigens getranscribeerd te worden op VeleHanden. Van 87 kronieken hebben we de transcriptie via een andere weg verkregen, en heeft de DBNL digitale bestanden gemaakt van die bestaande transcripties en eerdere edities. Wat betreft de kronieken die wel getranscribeerd moeten worden: meer dan 200 vrijwilligers werken daar gestaag aan door. Daarbij helpt de computer hen overigens wel: als we zo’n 30 getranscribeerde pagina’s van een kroniek hebben, trainen we daarmee in de software Transkribus een model. Transkribus is een computerprogramma dat werkt met Handwritten Text Recognition (HTR). Met andere woorden: het programma is in staat om te leren hoe het handschrift van een kroniekschrijver eruit ziet, en kan vervolgens zelf de rest van de pagina’s transcriberen.
Op deze manier neemt Transkribus veel werk van de vrijwilligers uit handen: als het programma al een pagina heeft getranscribeerd, hoeft een vrijwilliger niet zelf meer te puzzelen op een handschrift, maar enkel te controleren of de transcriptie die de computer gemaakt heeft, ook klopt. Inmiddels zijn er bijna 10.000 scans door de vrijwilligers getranscribeerd (of door de computer getranscribeerd en door de vrijwilligers gecontroleerd). Dat is een indrukwekkend aantal, maar we zijn er voorlopig nog niet: in totaal moeten er meer dan 34.000 scans getranscribeerd en gecontroleerd worden. Een dezer dagen komt de allerlaatste batch met kronieken, die zo’n 17.000 nieuwe scans bevat, online in het project.
Om die nieuwe hoeveelheid scans getranscribeerd te krijgen, is elke extra paar helpende handen enorm welkom. We willen proberen om elke dag 100 scans te transcriberen. Helpt u mee om die target te halen? Meld u hier aan voor ons project!
En ook als alles getranscribeerd is, dan hebben we nog steeds de hulp van enthousiaste vrijwilligers nodig, namelijk in deel twee van het project ‘Nieuws! Lokale kronieken, 1500-1850’.
Nieuws 2.0! Lokale kronieken, 1500-1850
In dit tweede VeleHanden-project gaan we de eerder getranscribeerde kronieken annoteren. Dat houdt in dat we belangrijke informatie in de tekst van een label voorzien, zodat we die informatie later systematisch kunnen ordenen en onderzoeken. Informatie die wij van een label willen voorzien zijn bijvoorbeeld vermeldingen van een datum, een persoonsnaam of een locatie. Ook willen we graag dat een afbeelding of tabel als zodanig gelabeld wordt, zodat we deze uiteindelijk eenvoudig terug kunnen vinden. Dit alles maakt het mogelijk om de teksten nog beter doorzoekbaar te maken, voor ons, en later ook voor anderen, want het is de bedoeling dat alle teksten en annotaties op termijn voor het publiek beschikbaar komen.
Bent u nieuwsgierig geworden? Over enkele weken, als er gaandeweg meer kronieken beschikbaar zullen komen in dit project, kunnen we uw hulp ook hier erg goed gebruiken! Hier vindt u de projectpagina. Daar kunt u ook de instructies inzien voor ons project. Weet u misschien andere mensen die het ook leuk zouden vinden om ons hiermee te helpen? Verwijs hen vooral door naar onze twee projecten!