Op woensdag 22 december 2021 hebben we het eerste algemene model gepubliceerd voor het automatisch herkennen van zeventiende-eeuwse Nederlandse handschriften!
De afgelopen jaren hebben vrijwilligers op Vele Handen heel veel scans getranscribeerd in ons project Nieuws! Lokale kronieken, 1500-1850 en ook in het project van het Amsterdamse Stadsarchief Crowd Leert Computer Lezen. Een groot deel van deze scans is nu gebruikt om de computer te trainen in het lezen van die lastige 17e-eeuwse handschriften. Het resultaat is een algemeen HTR (Handwritten Tekst Recognition) model Dutch_XVII_Century dat vandaag voor alle gebruikers van Transkribus gratis beschikbaar is gemaakt.
Eerder publiceerde het Nationaal Archief al zo’n algemeen model (IJsberg) voor de hele periode 1600-1800 en samen met het Stadsarchief Amsterdam kwam er zo’n algemeen model voor de 18e eeuw, (Dutch Mountains). Beide modellen deden het nog niet goed op gotische handschriften. Daarom wilden we een model trainen op basis van uitsluitend gotische handschriften. Zeventiende-eeuwse handschriften zijn voor een leek niet te lezen en ook doorgewinterde historici worstelen er nog wel mee.
Dutch_XVII_Century
In het nieuwe Transkribusmodel ‘Dutch_XVII_Century’ is een evenwichtige balans gezocht tussen handschriften van enerzijds Crowd Leert Computer Lezen en anderzijds Chronicling Novelty. Per handschrift zijn niet meer dan 300 scans aan dit algemene model toegevoegd. Het Stadsarchief Amsterdam leverde op deze manier trainingsmateriaal aan van veertien zeventiende-eeuwse notarissen: Bruijningh, Mathijsz, Westfrisius, Schaef, De Winter, Van der Groe, Anthony van de Ven, Van Sevenhoven, Des Pommare, Borsselaer, Pondt, De Vos, Joost van de Ven en Venkel. Chronicling Novelty leverde twintig verschillende kronieken, te weten uit: Antwerpen (1643), Den Bosch (1604), Brugge (1675, 1684), Brussel (1681), Gent (1666, 1668, 1668), Hauwert (1636), Ieper (1695), Leeuwarden (1671, 1697), Mechelen (1657, 1665), De Rijp (1652), Rotterdam (1648, 1658, 1663, 1690) en Zwolle (1681). In totaal bestaat het trainingsmateriaal voor het model ‘Dutch_XVII_Century’ uit scans 2965 van notarisakten en 1877 scans van kronieken. Samen goed voor 4842 scans met daarop 1.891.025 getranscribeerde woorden. Daarmee is het in één klap het grootste model voor Nederlandstalig materiaal en behoort het tot de grootste modellen in Transkribus.
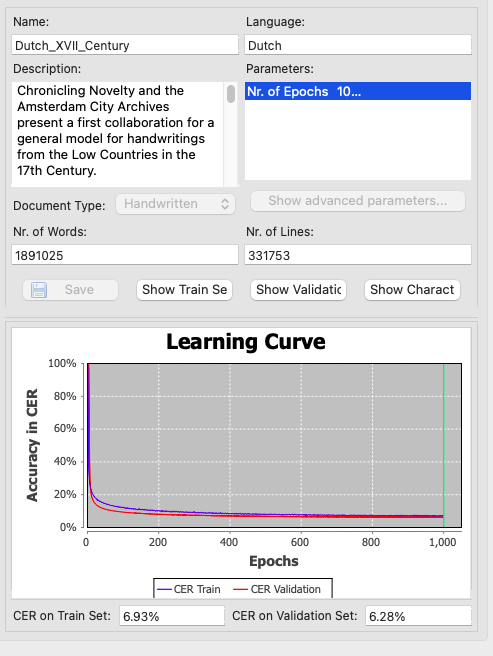
Probeer het heel eenvoudig zelf uit!
‘Dutch_XVII_Century’ werkt al heel aardig. De foutenmarge (ook wel Character Error Rate –kortweg CER- genoemd) bedraagt 6,28%. Het is getest op andersoortig materiaal zoals dagboeken en akten en de resultaten daarvan zijn veelbelovend. Nieuwsgierig geworden hoe goed dit model uw zeventiende-eeuwse bronnen transcribeert? Test dan hier of hier het nieuwe model (respectievelijk HTR+ en PyLaia)!
In de aanloop naar de publicatie van dit model zijn het Stadsarchief Amsterdam en Chronicling Novelty in gesprek geweest met diverse andere partijen die momenteel veel handgeschreven materiaal uit de zeventiende eeuw verwerken in Transkribus. Het idee is om in de toekomst met meer partijen samen te werken aan algemene modellen zodat we die CER verder omlaag krijgen en nog meer mensen hun lastig leesbare handschriften automatisch kunnen transcriberen in Transkribus.
